1385 Visitatori, 2 Utenti
mlodi, Lanch
Ciao, ospite!
(Login |
Registrati)
Teste Parlanti - Sintesi Vocale per Commodore 64
🤵
ready64
📅
22 gennaio 2025
Categoria: Articoli Esterni

Calcolatrice Telesensory Systems Inc. Speech+ (Courtesy of Nigel Tout)
Categoria: Articoli Esterni
I giochi parlanti hanno conquistato la loro giusta quota di primi posti nelle classifiche quest'anno. Il nostro esperto del suono, Tom Jeffries, è andato a Berkeley, in California, per parlare con gli specialisti del suono freelance che hanno inserito la sintesi vocale in Ghostbusters, Impossible Mission, Beach Head II e Kennedy Approach.
![]()
L'ultima novità nel campo dei videogiochi è la sintesi vocale. Al giorno d'oggi sono così tanti i titoli sul mercato ad utilizzare voci sintetizzate che abbiamo deciso di scoprire chi c'è dietro a tutta questa eloquenza digitale e di capire il motivo per cui le società di software ritengano che valga la pena includere la voce nei loro programmi e quali sono le implicazioni.
Quando i computer erano ancora macchine enormi e costose, disponibili solo per chi frequentava le grandi università e aziende, la sfida intellettuale di giocare contro una macchina doveva fare a meno di funzionalità avanzate di grafica e suono. La velocità di calcolo e lo spazio di memoria erano troppo costosi per gestire tali fronzoli, quindi i giochi mainframe erano (e sono) solitamente di solo testo.




I computer domestici hanno cambiato tutto. I fanatici della tecnologia sono esigenti per natura e non ci è voluto molto tempo prima che iniziassero ad esigere una grafica in stile arcade sui computer di casa, quindi sono stati aggiunti chip speciali e grandi quantità di memoria riservate solo alla grafica. Successivamente, anche il suono ha attirato la loro attenzione. All'inizio furono necessari dispositivi esterni per creare un output udibile, ma presto vennero trovati modi per incorporare la capacità sonora nei computer. Sia l'Apple II che il PC IBM utilizzano una delle prime e più semplici forme di suono integrato: un altoparlante guidato da una serie di impulsi on/off inviati tramite scrittura a una particolare posizione di memoria. I programmatori hanno creato alcuni suoni sorprendentemente complessi, incluso il parlato, utilizzando questo hardware primitivo.
Con il progredire dei computer domestici, sia le capacità grafiche che quelle audio migliorarono sempre di più. C'è stata una spinta costante verso un maggiore realismo all'interno dei giochi.
Esso... Parla
Quindi non sorprenderà che sempre più giochi per computer includano il suono di voci umane (e non). Prendiamo una copia di Kennedy Approach, Impossible Mission, Beach-Head II, Jump Jet o Ghostbusters e capiremo cosa si intende. Non solo la sintesi vocale viene utilizzata molto ampiamente, ma la qualità è sorprendentemente chiara e migliora costantemente.
Una buona sintesi vocale è molto difficile da ottenere; non mi ha sorpreso che la maggior parte delle software house abbia esternalizzato questo comparto. Mi ha sorpreso, tuttavia, scoprire che tutti i giochi sopra menzionati, ad eccezione di Jump Jet, avevano il parlato fornito da un'unica società: Electronic Speech Systems di Berkeley, California. Dato che abito a pochi chilometri di distanza, mi è sembrata una buona idea correre lassù e vedere se potevo scoprire il segreto del loro successo.

Forrest S. Mozer
La ESS nacque nel 1970 quando il padre di Todd Mozer, il dottor Forrest S. Mozer, un fisico spaziale dell'Università della California a Berkeley, sviluppò una tecnica per la sintesi vocale basata sulla riproduzione di una voce digitalizzata.
In precedenza si era ipotizzato che questo approccio avrebbe utilizzato una quantità di memoria proibitiva, ma il Dr. Forrest ha trovato il modo di comprimere i dati e ridurne le dimensioni fino a cento volte. Altri approcci si basano sulla creazione di un elaborato modello matematico della voce umana, che richiede uno speciale chip vocale dedicato o un processore centrale molto veloce, potente (e costoso) e produce una voce dal suono piuttosto meccanico (cartucce Currah Speech e Magic Voice Speech - Ndt).
Calcolatrice Telesensory Systems Inc. Speech+ (Courtesy of Nigel Tout)
L'algoritmo del Dr. Mozer mantiene le inflessioni naturali della voce umana e, nelle implementazioni attuali, può utilizzare qualsiasi microprocessore.
Inizialmente il Dr. Mozer si era concentrato sull'implementazione hardware delle sue idee. La sua tecnologia è stata utilizzata nella prima calcolatrice parlante per non vedenti e in un chip vocale prodotto dalla National Semiconductor. Quando i limiti di questo approccio cominciarono a manifestarsi, lui e i suoi soci iniziarono a concentrarsi sui modi per sintetizzare il parlato nel software con poco o nessun hardware aggiunto, il che portò alle tecniche utilizzate per riprodurre l'incredibile risata in Ghostbusters.
Attualmente ESS, oltre a fornire suoni agghiaccianti per i giochi per computer, produce prodotti di sintesi vocale per i principali produttori di apparecchiature elettroniche. Hanno appena finito un prodotto per AT&T che in grado di avvisare in caso di incendio o furto con scasso il proprietario di casa quando è assente e segnalerà il tipo di problema; stanno lavorando con un importante produttore di automobili su un sistema in grado di segnalare se il livello di olio è basso e comunicherà al proprietario o al suo meccanico, qual è il problema quando si rompe. Wow!
Come è fatto
Il sistema ESS (Electronic Speech Systems) è protetto da una dozzina di brevetti, quindi i dettagli rimangono segreti, ma possiamo riassumere per sommi capi l'approccio utilizzato. Per prima cosa, i tecnici iniziano registrando in alta qualità le parole che vogliono usare, con una voce che ritengono appropriata. (Ad esempio, per un programma educativo basato sul Libro della Giungla di Kipling hanno utilizzato uno studente indiano del Dr. Mozer.)
Quindi digitalizzano il suono (convertendolo dal formato analogico a quello digitale, formato da "1" e "0") e, utilizzando un mini-computer, processano l'audio sorgente fino a ridurlo a un centesimo della dimensione iniziale. Questo algoritmo di compressione è il cuore del loro sistema. È necessario uno sforzo considerevole per decidere quali informazioni possono essere eliminate e quali sono essenziali per il suono. Le informazioni originali di solito coinvolgono circa 10.000 campioni sonori completi al secondo; il prodotto finito utilizza tra 90 e 625 byte al secondo.
Sul Commodore 64, normalmente usano una velocità di 375 byte al secondo o meno, quindi è possibile inserire parecchio parlato in un programma.
Per realizzare la sintesi vocale sul Commodore 64, ESS utilizza il dispositivo audio della macchina, il chip SID, ma in un modo piuttosto insolito. Tutti i registri del SID sono spenti tranne il controllo del volume, che viene variato su e giù per ricreare la forma d'onda originale.
Poiché ci sono solo 16 impostazioni possibili, il suono risultante non potrà mai essere buono quanto un normale registratore, che ha la capacità di variazioni infinite, ma produce un parlato facilmente intelligibile.
La tecnologia di ESS può riprodurre gli accenti e le inflessioni dell'oratore originale in modo abbastanza accurato, come l'indiano nel Libro della Giungla, o può modificarli secondo necessità in modo che lo stesso vocabolario possa produrre una voce umana e una robotica.

Kennedy Approach
Tutta questa tecnologia è piuttosto impressionante, ma spetta alle società di software metterla in pratica. Ho chiesto a George Geary di MicroProse Software, editore di Kennedy Approach (una simulazione di controllo del traffico aereo), il motivo per cui MicroProse avesse deciso di utilizzare la sintesi vocale nel proprio programma, e la sua risposta è stata semplice e diretta: "Per migliorare il gioco". La voce della torre di controllo dell'aeroporto si alterna alle voci dei vari aerei nel dare e ricevere istruzioni e aggiunge davvero un notevole realismo alla simulazione. Ascoltate attentamente e noterete che le voci dei diversi piloti sono intonate in modo diverso: una inflessione sottile, ma ho scoperto che anche prima di rendermi conto che le voci erano diverse, il mio orecchio conosceva già la differenza.

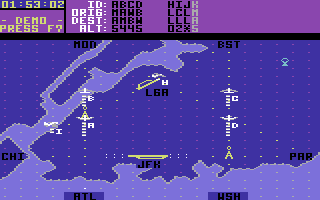
MicroProse, la cui digitalizzazione del parlato è stata eseguita da ESS, è così contenta del risultato finale in Kennedy Approach che sta attualmente aggiungendo una voce maschile e una femminile a Solo Flight in modo da poter ripubblicare una versione migliorata. Hanno intenzione di limitare l'uso della sintesi vocale a quei programmi che possono trarre un effettivo miglioramento, in termini di atmosfera, dall'utilizzo di questo espediente.

Altri usi del discorso sintetizzato sono più stravaganti. Nessuno sosterrebbe che la parola sia una parte necessaria di Ghostbusters, ma certamente aggiunge un tratto distintivo e tocco umoristico. Secondo Brad Fregger, direttore dello sviluppo software di Activision, volevano "dare al gioco la stessa sensazione del film" e la voce era un modo per raggiungere questo obiettivo.
Activision considera la voce "La ciliegina sulla torta: non tralasceremmo la torta per avere la ciliegina", ma in in questo caso c'era spazio per entrambi. Personalmente, sono contento: quale altro gioco dice "He slimed me!" quando sbaglio?
 Allo stesso modo, le voci in Jump Jet e Impossible Mission, pur aumentando il divertimento e il carattere del software, non sono essenziali per il gioco.
Allo stesso modo, le voci in Jump Jet e Impossible Mission, pur aumentando il divertimento e il carattere del software, non sono essenziali per il gioco.
Robert Botch, vicepresidente marketing di Epyx, ha detto che il discorso è stato inserito in Impossible Mission "per aggiungere qualcosa in più: un po' di realismo"; il grido che si sente quando il tuo personaggio cade attraverso uno dei buchi nel pavimento è sicuramente abbastanza realistico.
Un uso più serio della sintesi vocale è nei programmi educativi. Secondo Todd Mozer, questa è l'area in cui l'ESS prevede di vedere il maggiore utilizzo delle voci elettroniche in futuro. Ha detto: "Sono stati condotti molti studi sull'efficacia del parlato nell'apprendimento e i risultati sono stati estremamente positivi. I bambini si siedono davanti a un computer più a lungo se fornisce loro un feedback verbale e fornisce un meccanismo molto più efficace per l'insegnamento. Mi aspetterei che fosse un regno in cui la parola decolla." ESS ha già prodotto discorsi per diversi programmi educativi tra cui Talking Teacher di Imagic e Cave of the Word Wizard di Timeworks.
Il futuro
Qual è il prossimo passo nella battaglia senza fine per un maggiore realismo e maggiori vendite? Gli esperti sono stati quasi unanimi: tra non molto i computer saranno in grado di comprendere e rispondere al vostro discorso. Il riconoscimento vocale è estremamente difficile da realizzare a causa della complessità della lingua inglese e delle variazioni tra le voci, ma sono stati sviluppati diversi sistemi, incluso il sistema Covox Voicemaster per il Commodore 64. Mozer ritiene che prima o poi i produttori di computer potrebbero includere funzionalità di riconoscimento vocale come una parte del computer. Mi sembra divertente: mi vengono in mente un bel po' di cose da rispondere a quel fantasma che "he slimed me" in Ghostbusters.
Con la sintesi vocale e il riconoscimento vocale integrati, tu e il tuo Commodore potrete sedervi per una chiacchierata cuore a cuore o, più realisticamente, potrai utilizzare il vostro computer di casa, dotato di modem, come una segreteria telefonica intelligente. Non sorprende che ESS stia semplicemente dando gli ultimi ritocchi a un sistema che fa esattamente questo.
Se c'è qualche dubbio sul fatto che il parlato sintetizzato sia qui per restare o meno, controlla le specifiche della nuova macchina delle meraviglie della Commodore, l'Amiga. La sintesi vocale è integrata nell'Amiga e le società di software si stanno affrettando a metterla in pratica. Quindi abituiamoci a sentire il computer rispondere...
Tratto da Commodore User numero 25 (Ottobre 1985)
Articolo di Tom Jeffries
Note di traduzione:
- Aggiornate e aggiunte immagini all'articolo originale;
- Nomi scritti per esteso;
- Aggiunte note relativamente agli argomenti trattati;
- Catalogazione estensiva su Ready64 di tutti i videogame che contengono una Sintesi Vocale.
- Castle Raid! (AID, 1983), probabilmente il primo gioco per Commodore 64 con Sintesi Vocale (non confermato).

 Lo schermo del C64 e il raster
Lo schermo del C64 e il raster
🔒 Accedi o Registrati per commentare.